Black Magic
The world is a very different place from when I started this blog. The pandemic is over ... but I'm not sure we are in a better place. Different, not necessarily better. This brave new world has made it hard for me to find the time and mental energy to continue this blog. Moreover, with the changes at #EconTwitter (X), no one may read this anyway. Nonetheless, I move forward and we shall see if this post (and any future posts) provide utility to anyone beyond myself.
So, I have spent some time thus far this summer revising my lecture notes (available here ... although it is still in progress for some). I still stand firm in my belief that all empirical researchers ought to teach econometrics (if for no other reason as a constant reminder that there is more to the field than diff-in-diff). As I did so, I added two new extensions to my discussion of -- what else -- measurement error. But, this post is not about measurement error per se. Really. No, I mean it. Instead, it is about the truly awe-inspiring way that math works sometimes. It seems like sorcery. Dark magic kind of stuff.

The first example comes from Lubotsky & Wittenberg (2006). The authors consider the case of a linear regression model where the covariate of interest is not observed. In its place, the researcher has two proxies. As many out there in the ether have heard me say before, "proxy" is just a fancy name to make one forget that you have a measurement error problem. Chris Bollinger has been shouting this from the mountain top long before I (see, e.g., here).
Lubotsky & Wittenberg (L&W) are interested in how a researcher might optimally use two error-ridden proxies of the same unobserved covariate. There are, of course, a number of actions a researcher in such a situation may pursue. Instrumental variables is probably the one that most people think of... use one proxy to instrument for the other. Perhaps. However, to be a valid instrument, the measurement errors in the two proxies must be independent. That may not hold in many cases (particularly if the proxies suffer from nonclassical measurement error). But, I said this post was not really about measurement error.

I did.
So, back to L&W. They consider the following simple setup

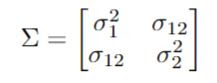


While this is nice, it is not (directly) useful since the variances of the measurement errors and their covariance are unobserved as well. But, now we get to the good part...

It turns out that if you estimate a bivariate regression using OLS (i.e., regress y on x1 and x2), then the expectation of the sum of the two coefficient estimates is identical to the expectation of the OLS coefficient estimate on x3 in a univariate regression using the optimal choice of λ!


[Go Mavs!]
The second example comes from Poirier & Ziebarth (2019). The authors consider the situation of merging data sets using non-unique strings. The running example in the paper is matching observations across Censuses (Censi?) by name (and perhaps other demographic characteristics). For instance, the researcher observes a 40 year old W.W. Waldo in the 2020 Census and you want to find this Waldo in the 2010 Census.

In the 2010 Census the researcher finds, say, five W.W. Waldos that are 30 years old. The regression model Poirier & Ziebath (P&Z) consider is
Y2020 = α + βX2010 + ε
So, Y2020 is known for Waldo. However, X2010 is not. Instead, we have five possible values for X2010; one from each of the 30 year old W.W. Waldo observed in 2010. What to do?
P&Z consider generating a proxy for X2010 that is the (arithmetic) average of X across the five possible matches and then regressing Y2020 on this average. As stated above, a proxy suffers from measurement error.
X-bar = X2010
+ μ
As such, one would certainly conjecture that the OLS estimates in the regression
Y2020 = α + βX-bar + η
will be biased. But, as Lee Corso says

OLS is unbiased!

It's true! OLS is unbiased under two conditions: the true W.W. Waldo must be among the set of five candidate Waldos used to form the average and the Xs are iid. That's it.
This is still a remarkable result. Even if the true Waldo is in the set, X-bar still suffers from measurement error. What is going on? I actually had to prove it to myself. I was like

Yes, way!

Since the Xs are iid, Var(X-bar) = Var(X)/5, where 5 is the size of the set of possible Waldos, and since one of X1,…,X5 is X2010, the numerator is also Var(X)/5. Bam! QED!



